ConcurrentHashMap解决了HashMap的线程不安全问题,在分析之前先介绍一个将HashMap线程安全的方法。利用Collections.synchronizedMAp方法调用内部类SynchronizedMap
1 2 HashMap<String, String> map = new HashMap<>(); Map m = Collections.synchronizedMap(map);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 private static class SynchronizedMap <K ,V > implements Map <K ,V >, Serializable { private static final long serialVersionUID = 1978198479659022715L ; private final Map<K,V> m; final Object mutex; SynchronizedMap(Map<K,V> m) { this .m = Objects.requireNonNull(m); mutex = this ; } SynchronizedMap(Map<K,V> m, Object mutex) { this .m = m; this .mutex = mutex; }
内部主要有两个变量,一个普通变量Map,还有一个互斥锁mutex。通过构造方法将外部的Map传入进去,如果没有要传入的mutex,则将引用this赋值给mutex,就产生了一个对象实例锁。之后,要操作Map的时候只要再外部添加一个synchronized关键字即可,很简单,但有时会影响性能。
1 2 3 4 5 6 7 8 9 10 11 12 public V put (K key, V value) synchronized (mutex) {return m.put(key, value);} } public V remove (Object key) synchronized (mutex) {return m.remove(key);} } public void putAll (Map<? extends K, ? extends V> map) synchronized (mutex) {m.putAll(map);} } public void clear () synchronized (mutex) {m.clear();} }
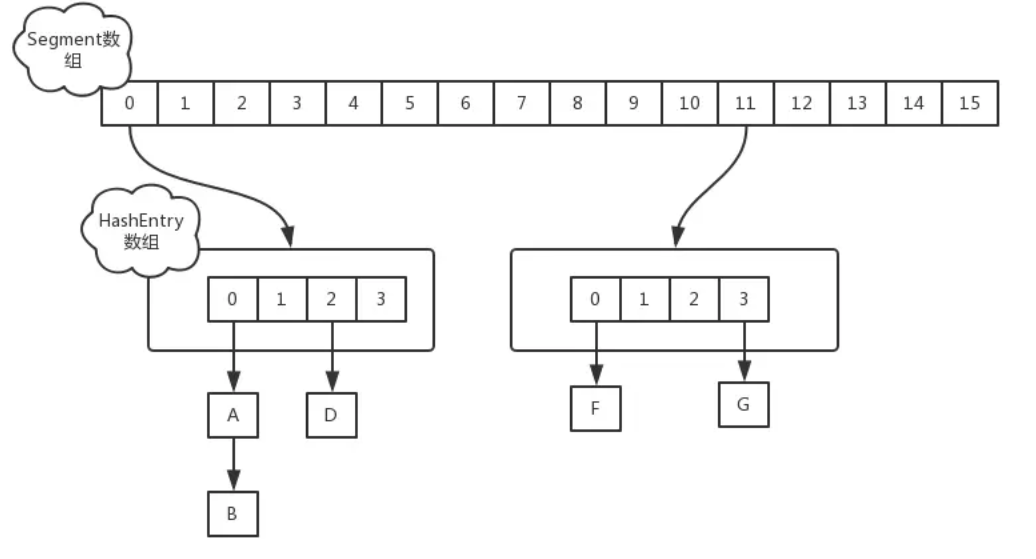
ConcurrentHashMap JDK1.7版本 在JDK1.7中,ConcurrentHashMap是由一个Segment数组和多个HashEntry组成,每一个Segment元素存储的是HashEntry数组和链表。它采用的是分段锁 技术。其中,Segment继承于ReentrantLock。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 static final int DEFAULT_INITIAL_CAPACITY = 16 ;static final float DEFAULT_LOAD_FACTOR = 0.75f ; final Segment<K,V>[] segmentsstatic final int DEFAULT_CONCURRENCY_LEVEL = 16 ; static final class Segment <K ,V > extends ReentrantLock implements Serializable transient volatile HashEntry<K,V>[] table; transient int count; transient int threshold; final float loadFactor; Segment(float lf, int threshold, HashEntry<K,V>[] tab) { this .loadFactor = lf; this .threshold = threshold; this .table = tab; } } static final class HashEntry <K ,V > final int hash; final K key; volatile V value; volatile HashEntry<K,V> next; } static final int MIN_SEGMENT_TABLE_CAPACITY = 2 ;final int segmentMask;final int segmentShift;
变量concurrentLevel表示并发数,默认是16,理论上最多可以同时支持16个线程并发写,只要它们的操作分别分布在不同的Segment上。这个值可以在初始化的时候设置为其他值,但是一旦初始化后,它是不可以扩容的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public ConcurrentHashMap (int initialCapacity, float loadFactor, int concurrencyLevel) if (!(loadFactor > 0 ) || initialCapacity < 0 || concurrencyLevel <= 0 ) throw new IllegalArgumentException(); if (concurrencyLevel > MAX_SEGMENTS) concurrencyLevel = MAX_SEGMENTS; int sshift = 0 ; int ssize = 1 ; while (ssize < concurrencyLevel) { ++sshift; ssize <<= 1 ; } this .segmentShift = 32 - sshift; this .segmentMask = ssize - 1 ; if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; int c = initialCapacity / ssize; if (c * ssize < initialCapacity) ++c; int cap = MIN_SEGMENT_TABLE_CAPACITY; while (cap < c) cap <<= 1 ; Segment<K,V> s0 = new Segment<K,V>(loadFactor, (int )(cap * loadFactor), (HashEntry<K,V>[])new HashEntry[cap]); Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize]; UNSAFE.putOrderedObject(ss, SBASE, s0); this .segments = ss; }
初始化可以得到:
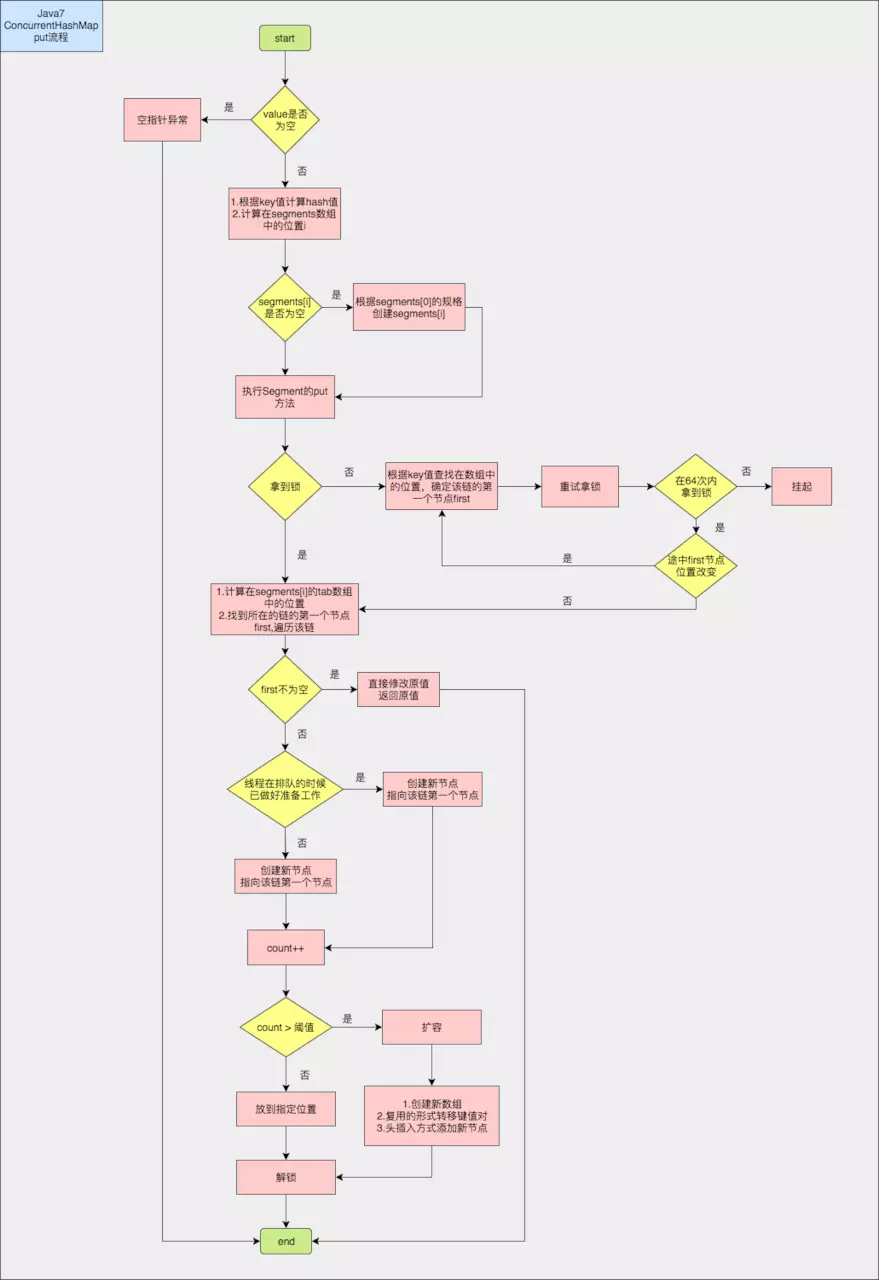
JDK1.7的put操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public V put (K key, V value) Segment<K,V> s; if (value == null ) throw new NullPointerException(); int hash = hash(key); int j = (hash >>> segmentShift) & segmentMask; if ((s = (Segment<K,V>)UNSAFE.getObject (segments, (j << SSHIFT) + SBASE)) == null ) s = ensureSegment(j); return s.put(key, hash, value, false ); }
当key为空时,会抛出异常。根据hash来找到对应的Segment,然后执行Segment内部的put操作。ensureSegment, 要初始化的下标j是大于0的,因为segment[0]在构造函数中已经初始化了,不会为空。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 private Segment<K,V> ensureSegment (int k) final Segment<K,V>[] ss = this .segments; long u = (k << SSHIFT) + SBASE; Segment<K,V> seg; if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null ) { Segment<K,V> proto = ss[0 ]; int cap = proto.table.length; float lf = proto.loadFactor; int threshold = (int )(cap * lf); HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap]; if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null ) { Segment<K,V> s = new Segment<K,V>(lf, threshold, tab); while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null ) { if (UNSAFE.compareAndSwapObject(ss, u, null , seg = s)) break ; } } } return seg; }
考虑到并发,会利用CAS机制来进行初始化,加载因子和数组长度和Segment[0]一致。之后,就进入这个segment进行put操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 final V put (K key, int hash, V value, boolean onlyIfAbsent) HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value); V oldValue; try { HashEntry<K,V>[] tab = table; int index = (tab.length - 1 ) & hash; HashEntry<K,V> first = entryAt(tab, index); for (HashEntry<K,V> e = first;;) { if (e != null ) { K k; if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { oldValue = e.value; if (!onlyIfAbsent) { e.value = value; ++modCount; } break ; } e = e.next; } else { if (node != null ) node.setNext(first); else node = new HashEntry<K,V>(hash, key, value, first); int c = count + 1 ; if (c > threshold && tab.length < MAXIMUM_CAPACITY) rehash(node); else setEntryAt(tab, index, node); ++modCount; count = c; oldValue = null ; break ; } } } finally { unlock(); } return oldValue; }
在执行put操作时首先调用tryLock尝试获得锁,如果获取失败就说明有其他线程竞争,则利用scanAndLockForPut()通过自旋获取锁。在里面如果重试的次数达到了max_scan_retries则改为阻塞锁获取,保证能获得成功。之后就是按照hashmap的1.7版本的put操作那样插入数据,即是按头插法插入的。最后是解锁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 private void rehash (HashEntry<K,V> node) HashEntry<K,V>[] oldTable = table; int oldCapacity = oldTable.length; int newCapacity = oldCapacity << 1 ; threshold = (int )(newCapacity * loadFactor); HashEntry<K,V>[] newTable = (HashEntry<K,V>[]) new HashEntry[newCapacity]; int sizeMask = newCapacity - 1 ; for (int i = 0 ; i < oldCapacity ; i++) { HashEntry<K,V> e = oldTable[i]; if (e != null ) { HashEntry<K,V> next = e.next; int idx = e.hash & sizeMask; if (next == null ) newTable[idx] = e; else { HashEntry<K,V> lastRun = e; int lastIdx = idx; for (HashEntry<K,V> last = next; last != null ; last = last.next) { int k = last.hash & sizeMask; if (k != lastIdx) { lastIdx = k; lastRun = last; } } newTable[lastIdx] = lastRun; for (HashEntry<K,V> p = e; p != lastRun; p = p.next) { V v = p.value; int h = p.hash; int k = h & sizeMask; HashEntry<K,V> n = newTable[k]; newTable[k] = new HashEntry<K,V>(h, p.key, v, n); } } } } int nodeIndex = node.hash & sizeMask; node.setNext(newTable[nodeIndex]); newTable[nodeIndex] = node; table = newTable; }
上面的代码先找出扩容前后需要转移的节点,先执行转移,然后在把该条链上剩下的节点转移。整体的put流程图如下:
get方法分析
jDK 1.8版本 在jdk1.8版本中ConcurrentHashMap利用CAS+Sychronized来确保线程安全,它的底层数组结构依然是数组+链表+红黑树重要属性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 transient volatile Node[] table;private transient volatile Node[] nextTable;private transient volatile long baseCount;private transient volatile int sizeCtl;private transient volatile int transferIndex;private transient volatile int cellsBusy;private transient volatile CounterCell[] counterCells;
重要内部类
1 2 3 4 5 6 7 static class Node implements Map .Entry final int hash; final K key; volatile V val; volatile Node next; ... }
value和next属性用volatile修饰保证了内存可见性,没有setValue方法直接改变Node的value属性
1 2 3 4 5 6 7 8 9 static final class ForwardingNode extends Node final Node[] nextTable; ForwardingNode(Node[] tab) { super (MOVED, null , null , null ); this .nextTable = tab; } ... }
ForwardingNode是一种临时节点只有扩容时使用,表明当前桶已做过处理。initTable方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 private final Node[] initTable() { Node[] tab; int sc; while ((tab = table) == null || tab.length == 0 ) { if ((sc = sizeCtl) < 0 ) Thread.yield(); else if (U.compareAndSwapInt(this , SIZECTL, sc, -1 )) { try { if ((tab = table) == null || tab.length == 0 ) { int n = (sc > 0 ) ? sc : DEFAULT_CAPACITY; @SuppressWarnings ("unchecked" ) Node[] nt = (Node[])new Node[n]; table = tab = nt; sc = n - (n >>> 2 ); } } finally { sizeCtl = sc; } break ; } } return tab; }
只有一个线程参与初始化过程,其他线程必须挂起;构造函数不初始化过程,初始化真正是在put操作触发。Thread.yield()操作让出CPU时间片。而正在进行初始化的线程会利用CAS操作将sizeCtl改为-1,创建出一个数组后,并将sizeCtl赋值为当前可用的数组大小。
put()方法 1.8 整体流程:initTable()进行初始化sychronized加锁,然后再进行一次判断当前节点是否发生变化,没有变化执行下面的方法;发生了变化直接跳转到第8步treeifyBin把这个链表转化为红黑树,但是不是大于8就转化为红黑树,当数组长度小于MIN_TREEIFY_CAPACITY(默认是64)时,进行扩容操作。
spread()方法
1 2 3 static final int spread (int h) return (h ^ (h >>> 16 )) & HASH_BITS; }
transfer 扩容操作 总体流程:bound变量是指该线程此次可以处理的区间的最小下标,超过这个下标,就需要重新领取区间或者结束扩容;advance变量是值是否转移到下一个桶,如果为true,表明该桶已经处理好了,向下一个桶推进;如果为false,说明还没有处理好当前桶,不能推进。ForwardingNode节点,用于告诉其他线程该桶已经处理了。
1 2 else if ((f = tabAt(tab, i)) == null ) advance = casTabAt(tab, i, null , fwd);
3.4)如果当前桶已经被其他线程处理了,当前线程处理到这个节点时,获得的hash值应该为-1(MOVED),则直接跳过,向前一个桶处理。
1 2 else if ((fh = f.hash) == MOVED) advance = true ;
4) 如果该桶没有被处理,则开始李勇sychronized加锁,然后再判断一下该桶的头节点是否发生了变化,没有发生变化继续执行。
1 2 synchronized (f) { if (tabAt(tab, i) == f) {
4.1)如果该桶存储的是链表的话int runBit = fh & n;是标识新增的位标志。然后开始对链表进行遍历。lastRun表示该节点及剩余的节点的新位置都是一样的,不需要再向下遍历,只要把这部分的头结点,即lastRun移动到新的位置,就能使剩余的部分都移到了新位置。此时的runBit表示该节点位置的标识,可能是1,也可能是0。
1 2 3 4 5 6 7 8 Node<K,V> lastRun = f; for (Node<K,V> p = f.next; p != null ; p = p.next) { int b = p.hash & n; if (b != runBit) { runBit = b; lastRun = p; } }
4.1.2)如果最后一个需要移动的节点是到原来的索引下标下,则将低位置头结点ln=lastRun;如果是到新的索引下标下,则将高位置头节点设置为hn = lastRun;。
1 2 3 4 5 6 7 8 if (runBit == 0 ) { ln = lastRun; hn = null ; } else { hn = lastRun; ln = null ; }
4.1.3)然后对链表进行遍历,知道最后一个需要移动的节点就终止,将节点分别插入到ln和hn,利用头插法插入。
1 2 3 4 5 6 7 for (Node<K,V> p = f; p != lastRun; p = p.next) { int ph = p.hash; K pk = p.key; V pv = p.val; if ((ph & n) == 0 ) ln = new Node<K,V>(ph, pk, pv, ln); else hn = new Node<K,V>(ph, pk, pv, hn); }
4.1.4 )分别将ln和hn插入到新数组,并将旧数组的该位置的节点变成ForwardingNode类型。之后,设置advance为true,表明该桶处理完了。
1 2 3 4 setTabAt(nextTab, i, ln); setTabAt(nextTab, i + n, hn); setTabAt(tab, i, fwd); advance = true ;
4.2)如果桶存储的是红黑树类型lo和hi,然后判断这个树如果小于6,就转化为链表,如果不是,则处理成标准的红黑树。之后,设置advance为true,表明该桶处理完了。
在旧数组中节点设置为ForwardingNode,表明该节点已经被处理了,里面的nextTable执行新的数组。
get()方法 先通过hash值获取在哪个桶,如果头节点的key相等,则返回值。如果hash小于0,表明该节点是ForwardingNode类型,已经发生了移动,则调用该类型节点的find方法查找;其他情况就是遍历链表记行查询。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public V get (Object key) Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek; int h = spread(key.hashCode()); if ((tab = table) != null && (n = tab.length) > 0 && (e = tabAt(tab, (n - 1 ) & h)) != null ) { if ((eh = e.hash) == h) { if ((ek = e.key) == key || (ek != null && key.equals(ek))) return e.val; } else if (eh < 0 ) return (p = e.find(h, key)) != null ? p.val : null ; while ((e = e.next) != null ) { if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek)))) return e.val; } } return null ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 Node<K,V> find (int h, Object k) { outer: for (Node<K,V>[] tab = nextTable;;) { Node<K,V> e; int n; if (k == null || tab == null || (n = tab.length) == 0 || (e = tabAt(tab, (n - 1 ) & h)) == null ) return null ; for (;;) { int eh; K ek; if ((eh = e.hash) == h && ((ek = e.key) == k || (ek != null && k.equals(ek)))) return e; if (eh < 0 ) { if (e instanceof ForwardingNode) { tab = ((ForwardingNode<K,V>)e).nextTable; continue outer; } else return e.find(h, k); } if ((e = e.next) == null ) return null ; } } }
参考文章:
图解ConcurrentHashMap 第四天:ConcurrentHashMap全解析(上) Java并发——ConcurrentHashMap(JDK 1.8) 深入分析ConcurrentHashMap1.8的扩容实现