
HashTable源码分析
2019年10月22日
Map的架构
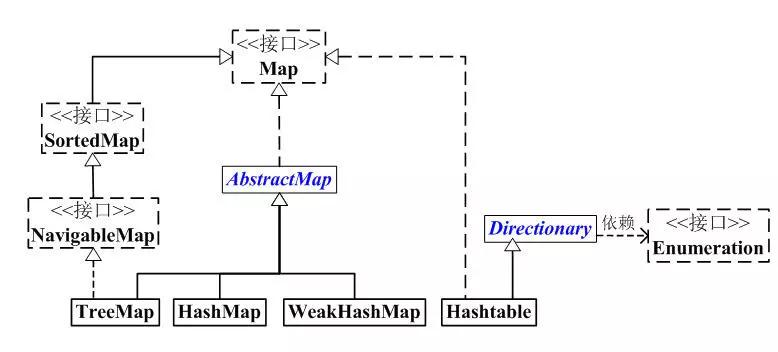
从上面图中可以看出,Map类型的子类主要有TreeMap、HashMap和HashTable等。
其中,TreeMap和HashMap主要继承的是AbstractMap,也同时实现了Map接口,而HashTable则继承了Directionary,同时也实现了Map接口。
HashMap和HashTable的内容都是键值对,都不保证次序,但HashMap是线程不安全的,而HashTable是线程安全的,它的key和value都不允许为空。
HashTable的继承情况如下:
1 | public class Hashtable<K,V> |
其中,Dictionary抽象类定义了键值对的基本操作。
1 | public abstract |
HashTable源码分析
- HashTable成员变量
1 | // 键值对数组 |
构造函数
HashMap的构造函数有四种形式,你可以手动设置数组的初始化容量和加载因子,如果没有设置,默认的初始化容量值为11,加载因子为0.75, 也可以将一个给定的同等类型的Map构造映射为新的HashTable.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor); if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1); }
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f); }
public Hashtable() {
this(11, 0.75f); }
public Hashtable(Map<? extends K, ? extends V> t) {
this(Math.max(2*t.size(), 11), 0.75f);
putAll(t); }判断是否包含该value
首先将该键值对数组赋值给tab数组,然后从尾到头逆向查找,然后在该位置的单向链表中进行依次查找,找到后返回true
1 | public synchronized boolean contains(Object value) { |
- 判断是否包含该key
在获取到该key的hash值后,会与0x7FFFFFFF执行按位与操作,这样做是为了保证index的第一位是0,也就是为了保证得到的是一个正数,因为有符号数的第一位是0时代表为正数,1表示为负数。
然后根据index找到该key所在数组中的位置,然后开始单向遍历该位置的链表。如果该节点的hash值与要查找的key的hash值相等,并且key值相等,则返回true。1
2
3
4
5
6
7
8
9
10public synchronized boolean containsKey(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return true;
}
}
return false; }
返回该key上的值的原理同上
1 | public synchronized V get(Object key) { |
- HashTable扩容
首先将原来table赋值给oldMap数组,然后将新的数组长度扩展为原来数组长度的2倍+1,如果超出最大值,将设置新的数组长度为最大值。之后,创建一个该新长度的数组。
修改次数+1,并设置新的阈值。
开始初始化HashTable,根据新的容量长度查找在新的数组的位置,之后采用头插法插入到该位置的单向链表的头部。
1 | protected void rehash() { |
- HashTable添加元素
首先它会判断该数组中是否含有该key值,如果有则进行值替换。
如果没有,则利用头插法插入到该数组位置的头结点。
1 | public synchronized V put(K key, V value) { |
- HashTable删除元素
如果删除的位置是某一单向链表的非头结点位置,则记录它的前一结点和下一结点,然后将前一结点的next指向它的下一结点。
如果是该链表的头结点的话,就将待删除结点的下一结点赋值给头结点。最后,设置待删除结点的值为null.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public synchronized V remove(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
("unchecked")
Entry<K,V> e = (Entry<K,V>)tab[index];
for(Entry<K,V> prev = null ; e != null ; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;
}
count--;
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null; }
HashTable与HashMap的不同
- 基类不同:HashTable基于Dictionary类,而HashMap是基于AbstractMap。
- null不同:HashMap可以允许存在一个为null和任意个为null的value,但是HashTable中的key和value都不允许为null。
- 线程安全:HashMap是单线程安全的,多线程不安全,而Hashtable是多线程安全的。
- 遍历不同:HashMap仅支持Iterator的遍历方式,而Hashtable支持Iterrator和Enumeration两种遍历放式。
- 存储结构: HashMap是数组+单向链表+红黑树,而HashTable是数组+单向链表